

Hva er Intility GPT?
I likhet med Chat GPT er Intility GPT en AI-chattetjeneste som lar deg ha en samtale med en stor språkmodell. Denne språkmodellen fungerer ved å generere den mest sannsynlige teksen basert på samtalen så langt. Intility GPT og Chat GPT har til felles at vi bruker de samme språkmodellene til å generere tekst, men likhetene stopper der.
Den store ulempen med Chat GPT er måten de bruker all dataen som brukerne sender inn. Alle chattemeldinger brukes til å videreutvikle både språmodellene og selve chattetjenesten. Det gjør at Chat GPT er uegnet for de som ønsker å benytte seg av dette verktøyet ved å sende inn privat eller sensitiv informasjon. Vi har utviklet vår egen chattetjeneste som har mange av de samme kapabilitetene som Chat GPT, men levert på en tryggere og mer brukervennlig måte.
Hva Intility GPT ikke er
En vanlig forvirring er at Intility GPT kan besvare spørsmål som en typisk Intility-ansatt vil kunne svare på, for eksempel spørsmål om en kundes miljø eller sakshistorikk. Intility GPT har ikke blitt fin-tunet på egen data, og har ikke tilgang til vår data om våre kunders miljø på noen måte. Intility GPT er laget for å fungere på samme måte som Chat GPT, men på en tryggere måte. Det vil si at man kan stille spørsmål hvor svaret ligger i treningsdataen til spåkmodellen som Open AI har brukt. Open AI har ikke tilgang til Intility sin data om våre kunder, og dermed vil ikke språkmodellen kunne gi noen svar på dette (vær obs på at den kan prøve å gi et svar, men dette vil være feil).
Hvorfor bruke Intility GPT?
Den største ulempen med gratis-versjonen av Chat GPT er at man ikke har noen kontroll på dataen man sender inn. Dataen kan brukes som treningsdata i fremtidige modeller, og da risikerer man å få denne dataen eksponert direkte eller indirekte. Dette problemet er løst i Enterprise versjonen av Chat GPT, men i tillegg til å være en kostbar tjeneste kjører den utelukkende på amerikanske datasentre. For selskaper med strenge krav til behandling av data kan dette være problematisk.
Intility GPT tilbyr den samme chattefunksjonaliteten, uten å bruke chattedataen som brukere sender inn. Brukere og selskaper som benytter seg av Intility kan derfor føle seg trygge på at det de sender ikke benyttes av Intility til videreutvikle verken språkmodeller eller andre tjenester.
Arkitektur
Overordnet arkitektur for Intility GPT er vist nedenfor. Selve chattetjenesten kjører på Intility sin platform, mens språkmodellene kjører i Azure.
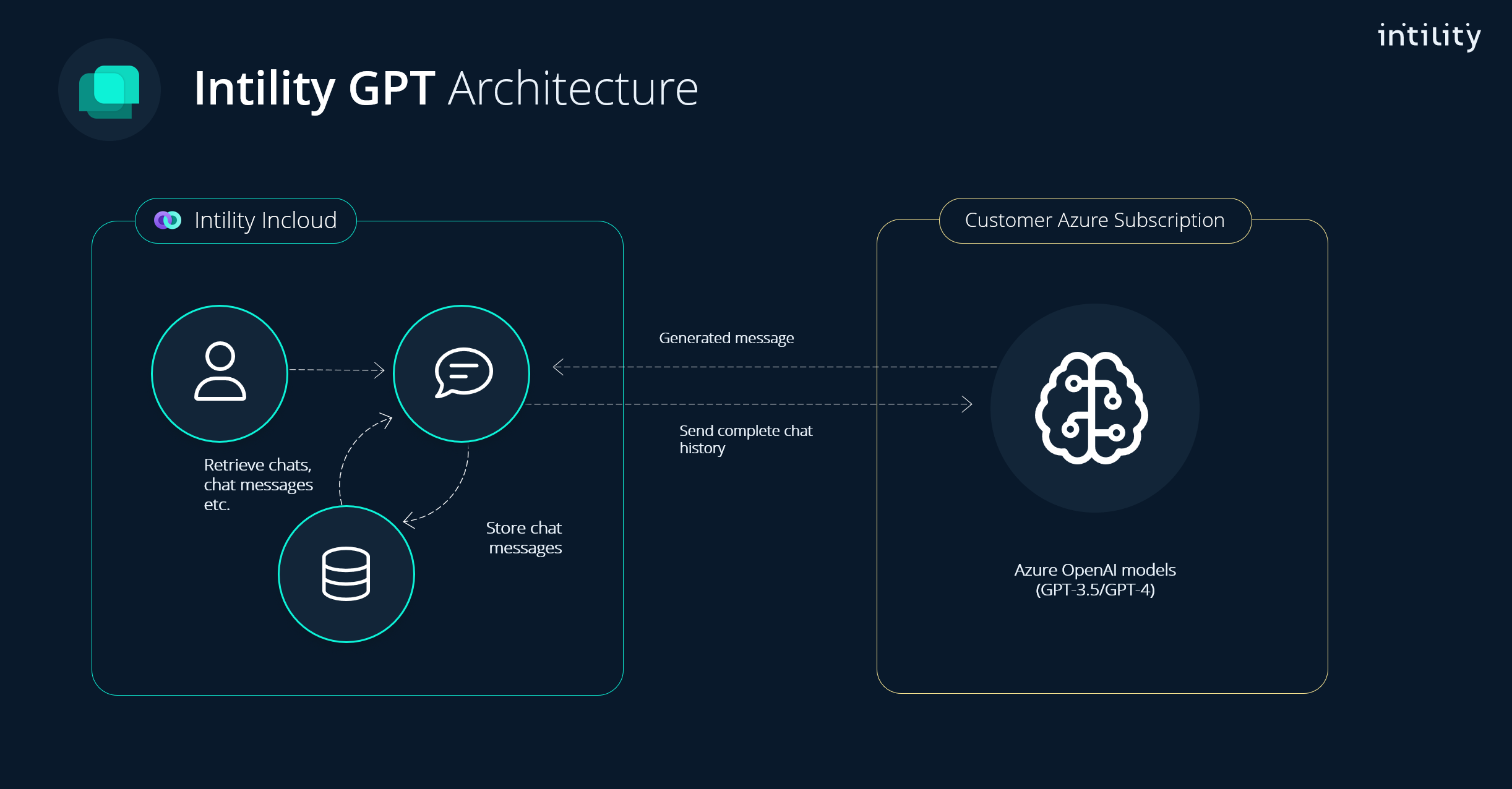
For å sikre en skalerbar og stabil tjeneste har vi valgt å sette opp dedikerte kundemiljøer i Azure. Det vil si at hver tenant har sine deployments av språkmodeller i Azure. Språkmodeller er en flaskehals da de krever mye regnekraft, og tilgjengelig regnekraft er begrenset per subscription. Ved å ha egne deployments i hver tenant sikrer vi at hver kunde får tilstrekkelig med kapasitet. Til tross for dette vil man i perioder kunne oppleve lang responstid grunnet mye trafikk mot Azure Open AI generelt. Dette vil trolig bedres etterhvert som Microsoft bygger ut sine datasentre.
All data, for eksempel chattehistorikk, lagres på servere hos Intility. API og chatteapplikasjon kjører i Intility sitt Openshiftmiljø.
Lagring og prosessering av data
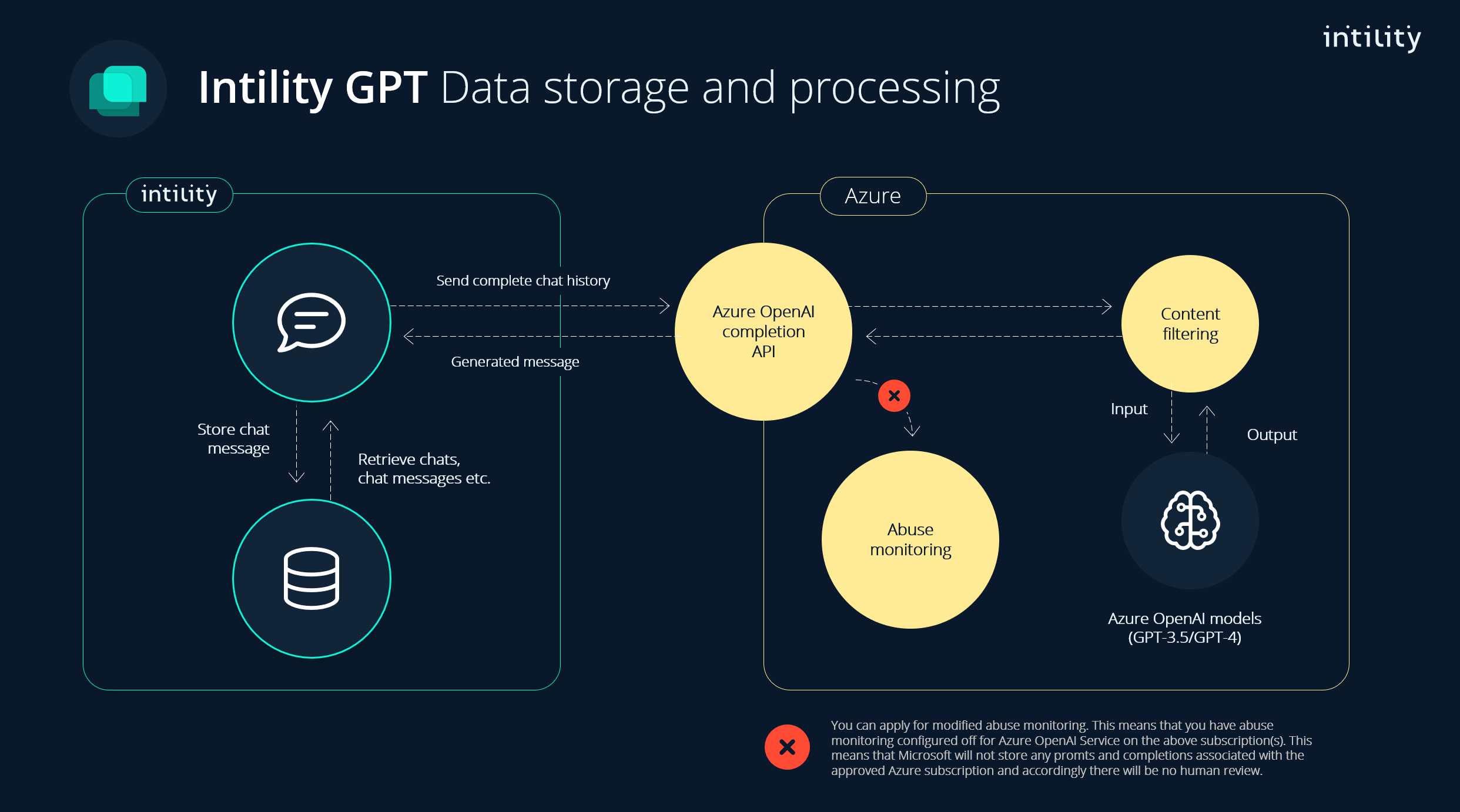
Figuren under viser hvordan data lagres og prosesseres i Intility GPT. Alt av chattemeldinger, chattehistorikk, etc. lagres hos Intility. Ved generering av nye meldinger fra språkmodellen, sendes data (alle meldinger i den aktuelle chatten) til Azure og prosesseres der. Azure vil logge alle forespørsler og har en retention på 30 dager for å kunne gjøre en monitorering av eventuell misbruk. Det er kun ved gjentagende misbruk at dataen kan inspiseres nærmere av Microsoft. Les mer om det her.
Kostnader
Store språkmodeller krever mye regnekraft, og er følgelig en kostbar tjeneste. Prismodellen er nokså komplisert og forbruket avhenger veldig av hva slags forespørsler man sender inn til språkmodellen. Vi har implementert Intility GPT med fokus på å ha en så forutsigbar kostnad som mulig, uten å sette begrensninger på bruken.
Kostnaden for Intility GPT er delt i følgende deler:
- Grunnkostnad: 2000,- per måned.
- Brukerkost: 50,- per bruker per måned
- Konsum av språkmodeller: Avhenger av bruk.
Kostnaden knyttet til forbruk av språkmodeller i Azure er beskrevet i detalj i denne artikkelen.
Anskaffelse av Intility GPT forutsetter at man har en Intility Managed Azure Landing Zone. Dersom dette allerede er på plass, vil det ikke medføre ekstra kostnader. Mangler man en Intility Managed Landing Zone, påløper det en fast månedskostnad på NOK 1500,-. Denne kostnaden danner også grunnlaget for fremtidige tjenester man måtte ønske å implementere i Azure, og kan dermed fordeles over flere tjenester enn kun Intility GPT. Les mer om Managed Azure Landing Zone her.
Hvordan kontrolleres kostnader i Intility GPT?
Det er en vanskelig balanse mellom funksjonalitet og kostnad. Ved ordinær bruk vil kostnadene være moderate, men enkelte bruksmønstre og målrettede forsøk på å bruke så mye som mulig vil kunne drive kostnadene i taket. Vi har derfor implementert følgende tiltak som vi mener skal kunne hindre ukontrollert bruk, og hvis uhellet er ute skal vi kunne begrense det.
- Rate limit på modellene i Azure Open AI. Ved å sette en øvre grense på hvor mange tokens per minutt (TPM), vi vil kunne etablere en øvre grense på forbruk. Denne grensen er dog statisk, så den vil være den samme hele døgnet og den må settes på et nivå som gjør at tjenesten er tilgjengelig også når bruken er høy.
- Maks antall chatter og meldinger per bruker per dag. En øvre grense vil redusere konsekvensene ved et eventuelt målrettet forsøk på et høyt konsum av språkmodeller. Nivået settes basert på historisk bruk, og vil ikke medføre noe utilgjengelighet ved normalt bruk.
- Varsling ved lange samtaler. Jo lenger chat, jo flere tokens kreves for å generere nye meldinger (og jo dyrere). Ved å varsle bruker når samtalen overstiger en viss lengde skaper vi bevissthet hos brukeren.
- Kostnadsalarmer i Azure. Vi vil monitorere bruken i Azure og agere når forbruket overstiger et forventet nivå, samt når forespeilet bruk i en måned overstiger et forventet nivå.
Andre tiltak vil vurderes forløpende.